Introduction
Nucleic acid metabolism refers to the processes by which nucleic acids (DNA and RNA) are synthesized or degraded within cells. These biopolymers consist of monomers called nucleotides. During synthesis, nucleotides are created through chemical reactions involving phosphate, pentose sugar, and a nitrogenous base. Purine synthesis produces adenine and guanine, while pyrimidine synthesis yields cytidine, uridine, and thymidine. Enzymes play a crucial role in both synthesis and degradation. Deficiencies in these processes can lead to various diseases. Overall, nucleic acid metabolism ensures accurate replication, expression, and regulation of genetic information. In this article we will see biosynthesis and catabolism of nucleotides, organization of mammalian genome, structure and function of DNA and RNA, DNA replication and RNA transcription.
Biosynthesis of purine and pyrimidine nucleotides
Nucleotide biosynthesis is a complex yet elegant process that ensures an ample supply of nucleotides for various cellular functions. These molecules play critical roles in genetic information storage, energy transfer, co-enzymes, and cellular signaling.
De Novo Synthesis of Purines
Purines (adenine and guanine) are essential components of DNA and RNA. The de novo pathway involves building purine nucleotides from simple precursor molecules. The process starts with inosine-5’-monophosphate (IMP), which serves as the precursor for both adenine and guanine.
Precursors: Aspartate, formate, glutamine, glycine, and bicarbonate act as building blocks for purine synthesis.
Here’s how they contribute:
- N1: Derived from the amino group of aspartate.
- C2 & C8: Derived from formate.
- N3 & N9: Derived from the amide group of glutamine.
- C4, C5 & N7: Derived from glycine.
- C6: Derived from HCO3- (bicarbonate).
IMP Synthesis
- IMP is formed by a series of enzymatic reactions.
- It serves as the precursor for both adenine and guanine.
Adenine Synthesis
IMP is converted to adenosine 5’-monophosphate (AMP):
- IMP → AMP via the addition of an amino group.
- AMP contains adenine.
Guanine Synthesis
IMP is converted to guanosine 5’-monophosphate (GMP):
- IMP → GMP via the addition of a carbonyl group.
- GMP contains guanine.
De Novo Synthesis of Pyrimidines
Pyrimidines are essential components of nucleic acids (both DNA and RNA), and their biosynthesis ensures an ample supply of these building blocks within cells. In summary, pyrimidine biosynthesis is a tightly regulated process that ensures the availability of these essential molecules for genetic information storage, energy transfer, and cellular signalling.
Overview
- Unlike purines, pyrimidines are synthesized as bases first, and then they are attached to ribose sugar.
- The process involves constructing the pyrimidine ring before linking it to ribose-5-phosphate.
Precursors
The key precursors for pyrimidine synthesis are carbamoyl phosphate and aspartate.
Here’s how they contribute:
- Carbamoyl Phosphate: Derived from CO₂ and NH₄⁺.
- Aspartate: Provides the amino group for the pyrimidine ring.
Steps in Pyrimidine Synthesis
The pathway includes several enzymatic reactions:
- Carbamoyl Phosphate Synthesis: Catalyzed by carbamoyl phosphate synthetase II.
- Pyrimidine Ring Formation: The pyrimidine ring is constructed.
- Ribose Sugar Addition: The ribose-5-phosphate is added to complete the nucleotide structure.
Specific Pyrimidines
- Uracil, thymine, and cytosine are the three primary pyrimidines.
- Uracil is a component of RNA.
- Thymine is found in DNA (replacing uracil).
- Cytosine is present in both RNA and DNA.
Deoxyribonucleotides
Before pyrimidine bases can be used for DNA synthesis, ribose must be converted to deoxyribose.
Catabolism of Purine Nucleotides
Purine catabolism refers to the breakdown of purine nucleotides (such as AMP, IMP, XMP, and GMP) into simpler components. The end product of purine metabolism in humans is uric acid.
Steps Involved
- Dephosphorylation: Nucleotide monophosphates (AMP, IMP, XMP, and GMP) are dephosphorylated into their corresponding nucleosides (adenosine, inosine, xanthosine, and guanosine) by the enzyme nucleotidase.
- Deamination: The amino group from AMP or adenosine can be removed to produce IMP or inosine.
- Glycosidic Bond Cleavage: Nucleosides are further degraded by the enzyme Purine Nucleoside Phosphorylase (PNP), resulting in the release of the purine base and ribose-1-P.
- Conversion to Uric Acid: The PNP products (adenosine and inosine) are merged into xanthine by guanine deaminase and xanthine oxidase. Xanthine is then oxidized to uric acid by xanthine oxidase.
Hyperuricemia
- Hyperuricemia occurs when there is an excess of uric acid in the blood.
- Uric acid tends to clump together in sharp crystals.
- These crystals can settle in joints, causing gout, a painful form of arthritis.
- Additionally, uric acid crystals can build up in the kidneys, leading to the formation of kidney stones.
Gout Disease
Gout is characterized by sudden and severe joint inflammation due to the deposition of uric acid crystals.
Symptoms of a gout attack include:
- Intense joint pain.
- Discoloration or redness.
- Stiffness
- Tenderness
- Swelling
- Warmth in the affected joint.
Men are more likely to develop gout than women.
Treatment involves lifestyle changes (diet modification, hydration) and medications to lower uric acid levels.
How Hyperuricemia Affects the Body
Initially, hyperuricemia may not cause noticeable symptoms. Managing hyperuricemia through lifestyle adjustments and medical intervention can prevent complications and improve overall health.
Over time, elevated uric acid levels can lead to pain and damage in various body parts:
- Bones
- Joints
- Tendons
- Ligaments
High uric acid levels are also associated with other health conditions:
- Kidney disease
- Heart disease
- High blood pressure
- Diabetes
- Fatty liver disease
- Metabolic syndrome.
Organization of mammalian genome
The eukaryotic genome (including mammals) is organized at multiple levels:
- Nuclear Processes: These include transcription, RNA processing, DNA replication, and DNA repair. These essential cellular functions occur within the nucleus.
- Chromatin Organization: Chromatin refers to the complex of DNA and proteins (such as histones) that make up chromosomes. It is structured at a higher level than in prokaryotes.
- Chromosome Orientation: The spatial arrangement of chromosomes within the nucleus.
Euchromatin
- Lightly packed chromatin enriched in genes.
- Often under active transcription (but not always).
- Constitutes 92% of the human genome.
Heterochromatin
- Densely compacted DNA.
- Comes in multiple variants:
- Facultative heterochromatin: Variable expression.
- Constitutive heterochromatin: Consistently repressed.
- Both play roles in gene expression.
Three-Dimensional Genome Organization
- Recent research focuses on understanding the 3D organization of mammalian genomes.
- Major tools map this structure, revealing hierarchical arrangements in different cell types.
In summary, the mammalian genome is intricately organized, with distinct regions for gene expression, chromatin structure, and spatial positioning within the nucleus.
Structure and function of DNA
DNA (Deoxyribonucleic acid) is a remarkable molecule that carries the genetic instructions for all known organisms and many viruses. Here’s the lowdown on its structure:

Double Helix
Imagine DNA as a twisted ladder—a double helix. The two strands wind around each other, forming the sides of the ladder. These strands are composed of nucleotides, which are the building blocks of DNA.
Nucleotides
Each nucleotide consists of three components:
- Phosphate Group: A phosphate molecule.
- Sugar (Deoxyribose): A sugar molecule.
- Nitrogenous Base: One of four nitrogen-containing bases: adenine (A), thymine (T), guanine (G), or cytosine (C).
Base Pairs
The rungs of our DNA ladder are made up of pairs of nitrogenous bases. These base pairs follow specific rules:
- Adenine (A) pairs with thymine (T).
- Guanine (G) pairs with cytosine (C).
Complementary Strands
The two strands are complementary. If you know the sequence of one strand, you can deduce the sequence of the other. This property is crucial during DNA replication and transcription.
Antiparallel Arrangement
The two strands run in opposite directions—like parallel roads but going opposite ways. This antiparallel arrangement ensures stability.
Functions of DNA
Store and Transmit Genetic Information (Inheritance): DNA’s primary job is to carry the hereditary instructions from one generation to the next. It’s like a molecular time capsule, passing on the genetic code that shapes our traits, behaviors, and more.
Protein Synthesis: DNA plays a starring role in protein production. Here’s how it works:
- Transcription: Enzymes read specific segments of DNA and create a complementary RNA copy (called messenger RNA or mRNA).
- Translation: Ribosomes (the protein factories) use this mRNA as a template to assemble amino acids into proteins. Each triplet of nucleotides (a codon) in the mRNA corresponds to a specific amino acid.
Copying DNA (Replication): Before a cell divides, it needs to duplicate its DNA. Enzymes unzip the double helix, and each strand serves as a template for creating a new complementary strand. Voilà—two identical DNA molecules!
Genetic Diversity: DNA isn’t just about sameness; it’s also about variation. Mutations—changes in the DNA sequence—introduce diversity. Some mutations are neutral, while others drive evolution.
Regulating Gene Functions: DNA isn’t a static library; it’s a dynamic script. Regulatory regions control when and where specific genes are turned on or off. Think of them as dimmer switches for gene expression.
Structure of RNA
RNA (Ribonucleic acid) is a fascinating molecule that complements DNA in various ways. Here’s the lowdown on its structure:
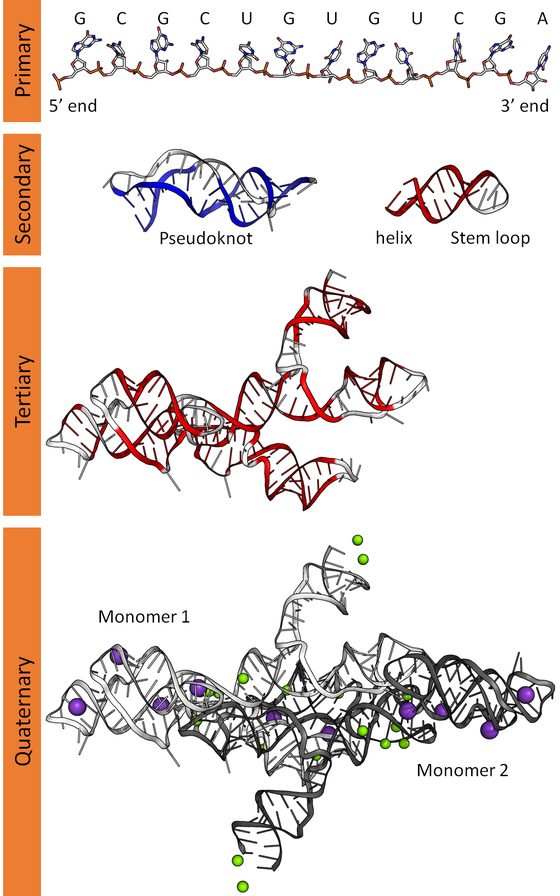
Single-Stranded: Unlike DNA’s double helix, RNA typically exists as a single-stranded biopolymer. It’s made up of ribonucleotides, which are linked together by phosphodiester bonds.
Ribonucleotide Components
- Ribose Sugar: The backbone of RNA contains ribose—a pentose sugar with five carbons and one oxygen. This sugar provides the scaffold for the entire molecule.
- Nitrogenous Bases: RNA has four nitrogenous bases:
- Adenine (A)
- Guanine (G)
- Cytosine (C)
- Uracil (U)—which replaces thymine (T) found in DNA.
Base Pairing and Folding
Self-complementary sequences within the RNA strand lead to intrachain base-pairing. This allows RNA to fold into complex structural forms, including bulges and helices. The three-dimensional structure of RNA is critical—it determines stability and function.
Chemical Lability
RNA is more chemically reactive than DNA due to the presence of a hydroxyl (−OH) group attached to the second carbon in the ribose sugar. This reactivity makes RNA prone to hydrolysis, which contrasts with DNA’s relative stability.
Functions of RNA
- Messenger RNA (mRNA): Carries genetic information from DNA to ribosomes during protein synthesis.
- Transfer RNA (tRNA): Transports amino acids to the ribosome, ensuring accurate protein assembly.
- Ribosomal RNA (rRNA): Forms the core structure of ribosomes, where protein synthesis occurs.
- MicroRNA (miRNA): Regulates gene expression by binding to specific mRNA sequences.
- And there’s more—RNA plays roles in splicing, telomere maintenance, and viral replication
DNA replication (semi conservative model)
Origins of Replication
DNA replication kicks off at specific sites called origins of replication. These are like starting points on the DNA strand. In eukaryotic cells (like ours), there are multiple origins along each chromosome. Prokaryotic cells (like bacteria) have a single origin.
Unwinding the Double Helix
Imagine DNA as a twisted ladder. The first step is to unzip this ladder. An enzyme called helicase unwinds the double helix by breaking the hydrogen bonds between complementary base pairs. As helicase does its thing, it creates a Y-shaped structure called the replication fork.
Priming the Template Strand
Now, we need a starting point for DNA synthesis. Enter primase, another enzyme. Primase lays down a short RNA primer—a sort of “Here’s where replication begins!” sign—on the template strand.
Building New Strands
DNA polymerase—the superstar of replication—slides along the template strand, adding complementary nucleotides. Remember the base-pairing rules: A pairs with T, and C pairs with G. There are two strands: the leading strand (which grows continuously) and the lagging strand (which grows in chunks called Okazaki fragments).
Proofreading and Repair
DNA polymerase is a perfectionist. It proofreads as it goes, fixing any mistakes. If it spots an incorrect base, it snips it out and replaces it with the right one.
Okazaki Fragments and Ligase
On the lagging strand, DNA polymerase works in reverse, creating Okazaki fragments. These fragments need to be stitched together. That’s where DNA ligase comes in. It seals the gaps between fragments.
Semi-Conservative Magic
The semi-conservative model says that each new DNA double helix consists of one old strand (from the original DNA) and one new strand (freshly synthesized). So, after replication, you get two identical DNA molecules, each with a mix of old and new strands.
Meselson-Stahl Experiment
In the late 1950s, scientists Meselson and Stahl conducted a brilliant experiment. They grew bacteria in heavy nitrogen (15N) and then switched them to light nitrogen (14N). The DNA replicated in a semi-conservative manner, as confirmed by ultracentrifugation.
Life’s Copy Machine
DNA replication ensures that every cell division produces accurate copies of genetic information.
Transcription or RNA synthesis
Initiation
- Our story begins at the promoter region—a DNA sequence near the gene that’s about to be transcribed. Imagine it as the red carpet rolled out for our RNA polymerase.
- RNA polymerase, our lead dancer, waltzes in and binds to the promoter. This marks the start of transcription.
- The DNA double helix unwinds, creating a transcription bubble. One of the exposed DNA strands—the template strand—will guide our RNA creation.
Elongation
- RNA polymerase pirouettes along the template strand, adding complementary RNA nucleotides. A is still paired with U (uracil), C with G.
- As the dance progresses, our RNA strand elongates. It’s like choreographing a new sequence based on the old DNA steps.
- The nontemplate strand (also called the coding strand) watches from the sidelines, cheering on its partner.
Termination
- The music changes. RNA polymerase encounters a termination signal—a specific DNA sequence that whispers, “Time to wrap it up!”
- The RNA transcript is complete. It’s like the final pose in a ballet—graceful and precise.
- RNA polymerase takes a bow, releases the RNA, and exits the stage.
Editing and Polishing
- Our freshly minted RNA isn’t camera-ready yet. It needs a cap (like a backstage pass) at the beginning and a poly-A tail (a fashionable accessory) at the end.
- Plus, there’s a bit of splicing to do. Introns (non-coding regions) are snipped out, leaving only the exons (the meaningful dance moves).
Types of RNA
- mRNA (Messenger RNA): The star of the show. It carries the genetic message from the nucleus to the ribosome, where proteins are made.
- tRNA (Transfer RNA): The backstage crew. It brings amino acids to the ribosome, ensuring the choreography matches the music.
- rRNA (Ribosomal RNA): The stage itself. It forms the ribosome, where protein synthesis happens.
Why This Matters
- Transcription is like writing down the recipe for a gourmet meal. The DNA recipe card stays safe in the nucleus, while the RNA copies heads to the kitchen (ribosome).
- Proteins—the chefs, waiters, and flavor enhancers—are made according to this recipe. They run the show in our cellular restaurant.
Genetic Code: The Language of Life
The genetic code is like the universal Rosetta Stone for living organisms. It’s the set of rules that translates the language of nucleotides (those A’s, T’s, C’s, and G’s in DNA or RNA) into the language of amino acids—the building blocks of proteins.
- Codons: Imagine DNA or RNA as a long string of letters. Each group of three nucleotides is called a codon. These codons act as the genetic alphabet, spelling out instructions for protein synthesis.
- Amino Acids: There are 20 different amino acids that make up proteins. The genetic code assigns specific codons to each amino acid. For example:
- AUG codes for methionine (the start codon).
- UUU codes for phenylalanine.
- GGC codes for glycine.
Translation: From Nucleotides to Amino Acids
Now, let’s see how this code gets translated into actual proteins:
Transcription (Prequel):
- In the cell nucleus, an enzyme called RNA polymerase reads the DNA code and creates a complementary messenger RNA (mRNA) strand.
- This mRNA carries the genetic instructions from the nucleus to the ribosomes (the protein factories) in the cytoplasm.
Translation (The Main Event):
- Our mRNA arrives at the ribosome, where the real magic happens.
- Transfer RNA (tRNA) molecules waltz in, each carrying a specific amino acid. These tRNAs have anticodons—complementary to the mRNA codons.
- The ribosome lines up the mRNA codons with the tRNA anticodons. It’s like a synchronized dance floor where codons and anticodons pair up.
- As the ribosome moves along the mRNA, it stitches together the amino acids carried by the tRNAs. The polypeptide chain grows, step by step.
Finale: The Protein!
- The ribosome keeps reading the mRNA until it hits a stop codon (UAA, UAG, or UGA). These codons signal the end of the protein.
- The newly formed polypeptide chain folds into its unique three-dimensional shape—a protein with a specific function.
Protein Synthesis Inhibitors
Sometimes, uninvited guests show up at the protein synthesis party. These are protein synthesis inhibitors—compounds that disrupt the process. Here’s how they gate-crash:
Targeting Ribosomes: Most inhibitors mess with the ribosome’s groove. They can:
- Bind to the ribosomal subunits, preventing them from coming together.
- Interfere with tRNA binding, so amino acids can’t be added.
Examples
- Antibiotics: Ever heard of tetracycline or erythromycin? Yep, they’re ribosome-wreckers.
- Toxins: Some bacterial toxins (like ricin) specifically target ribosomes, causing chaos.
Summary
Nucleic Acid Metabolism and Genetic Information Transfer govern the very essence of life. Within our cells, the intricate dance of purine and pyrimidine nucleotides unfolds. Purines (adenine and guanine) are meticulously synthesized from ribose 5-phosphate, while pyrimidines (cytosine, thymine, and uracil) follow simpler pathways. But it doesn’t end there—catabolism of purines leads to uric acid, and elevated levels can trigger the fiery pain of gout. Meanwhile, our mammalian genome—organized within linear chromosomes—houses protein-coding regions, gene regulators, and mysterious intergenic stretches. And let’s not forget the iconic duo: DNA and RNA. DNA’s double-stranded helix cradles our genetic blueprint, while RNA—single-stranded and versatile—shuttles messages and orchestrates protein synthesis. In the semi-conservative waltz of DNA replication, each daughter molecule inherits a mix of old and new strands. Transcription, led by RNA polymerase, transcribes DNA into RNA (mRNA), setting the stage for translation. The genetic code, inscribed in codons, guides ribosomes as they assemble amino acids into intricate proteins.
For more regular updates you can visit our social media accounts,
Instagram: Follow us
Facebook: Follow us
WhatsApp: Join us
Telegram: Join us